Parameteridentifikation: ein klassisches Inverses Problem
Parameteridentifikation ist ein zentrales Thema in der Inversen Theorie. Dabei geht es um die Bestimmung einer unbekannten Funktion. Im Folgenden wird ein typisches Szenario behandelt: die Bestimmung einer unbekannten Parameterfunktion \( \lambda \) aus gegebenen Daten \( y \), die über einen Integraloperator \( \mathcal{A} \) mit \( \lambda \) verknüpft sind. Die zugrunde liegende Operatorgleichung ist linear, das numerische Verfahren basiert auf einer Diskretisierung mittels Trapezregel und der Lösung eines linearen Gleichungssystems.
Die Problemstellung geht auf einen Beitrag von Kirsch[1] im Sammelband Trends in Mathematical Optimization zurück und eignet sich gut, um grundlegende Phänomene inverser Probleme – insbesondere Instabilität, schlechte Konditionierung und die Notwendigkeit von Regularisierung – anschaulich darzustellen. Der Text baut auf einer früheren Version auf und wurde um eine präzisere Darstellung der adjungierten Abbildung sowie ihrer konsistenten Diskretisierung erweitert.
Das Problem
Gegeben sei
\[
(\mathcal{A}\lambda ) (t) = \int_0^1 \lambda(s) \, e^{ts} \, ds, \qquad t \in [0,1] \tag{1}
\]
Man kann zeigen, dass zu jeder Funktion \( y \) aus einem bestimmten Funktionenraum \( X (=L^2[0,1]) \) genau ein \( \lambda \) (aus \( X \)) existiert mit \( \mathcal{A} \lambda = y \), d. h. \( \mathcal{A} \) ist eine Bijektion.
Als konkretes Beispiel sei \( \lambda(t) = e^t \). So ist
\[
y (t) := \mathcal{A} (e^t) = \frac{1}{t+1} \left( e^{t + 1} – 1 \right), \qquad t \in [0,1] \tag{2}
\]
Wir ändern nun den Blickwinkel und betrachten \( \lambda \) als „Parameterfunktion“, die es zu bestimmen gilt, wobei die Kenntnis der Funktion \( y \) aus (2) vorausgesetzt wird. Dazu sei das folgende numerische Verfahren gewählt:
Diskretisierung
- Ersetze das Integral (den Operator \( \mathcal{A} \)) durch die summierte Trapezregel (eine Diskretisierung des Problems).
- Die Unterteilung \( 0 = x_0 < x_1 < \ldots < x_{n-1} < x_n =1 \), \( n > 0 \) führt zu
\[
T_n(f, [0,1]) := \sum_{j=0}^{n-1} \frac{x_{j+1} – x_j }{2} \left( f(x_j) + f(x_{j+1}) \right)
\]
Mit \( x_i = i h \), \( h=1/n \) ist
\[
T_n(f, [0,1]) = \frac{1}{2n} \left( f(0) + f(1) \right) + \frac{1}{n} \sum_{j=1}^{n-1} f(x_j) \tag{3}
\]
und es gilt eine Fehlerabschätzung (\( f \in C^2[0,1] \)) der Form
\[
T_n(f, [0,1]) – \int_0^1 f(s) \, ds = \frac{h^2}{12} f^{(2)}(\xi), \quad \text{für ein } \xi \in (0,1)
\] - Die summierte Trapezregel für (1) lautet demnach
\[
\int_0^1 \lambda(s) \, e^{ts} \, ds \approx \frac{1}{2n} \left( \lambda(0) + \lambda(1) e^{t} \right) + \frac{1}{n} \sum_{j=1}^{n-1} \lambda(x_j) e^{t x_j} \tag{4}
\]
Gesucht sind daher die Funktionswerte von \( \lambda \) in den Stützstellen \( x_i \). Gegeben ist die Funktion \( y \). Zur Bestimmung der \( n+1 \) unbekannten Werte \( \lambda_i := \lambda(x_i) \) haben wir die (semi-diskrete) Gleichung
\[
\frac{1}{2n} \left( \lambda(x_0) + \lambda(x_n) e^{x_i} \right) + \frac{1}{n} \sum_{j=1}^{n-1} \lambda(x_j) e^{x_i x_j} = y(x_i), \quad i=0,\ldots,n
\]
bzw. als lineares Gleichungssystem geschrieben
\[
\mathbf{A}_n \boldsymbol{\alpha} = \mathbf{y} \tag{5}
\]
mit
\[
a_{ij} =
\begin{cases}
\frac{1}{2n} e^{x_i x_j} & j = 0 \text{ oder } j = n \\\\
\frac{1}{n} e^{x_i x_j} & \text{sonst}
\end{cases}
\]
und
\[
\mathbf{y} = \left( y(x_i) \right)_{i=0}^n ,\qquad \boldsymbol{\alpha} = \left( \lambda(x_i) \right)_{i=0}^n
\]
Obwohl der Operator \( \mathcal{A} \) im kontinuierlichen Fall selbstadjungiert ist, ist die Matrix \( \mathbf{A}_n \) im Allgemeinen nicht symmetrisch. Grund dafür sind die unterschiedlichen Gewichte der Trapezregel an den Rändern. Zum Beispiel: \( a_{01} = \frac{1}{n} \), aber \( a_{10} = \frac{1}{2n} \).
Numerische Lösung der Parameteridentifikation
Für verschiedene \( n \) wurde die Kondition der Matrix \( A_n \) bestimmt, das Gleichungssystem (5) aufgestellt und gelöst. \( \alpha(t) \) sei die durch den Vektor \( \alpha \) gegebene stückweise lineare Funktion. Die Kondition, der absolute Fehler \( \| \alpha(t) – e^t \|_\infty \) und der relative Fehler \( \| \alpha(t) – e^t \|_\infty / \| e^t \|_\infty \) sind in Tabelle 1 aufgeführt.
Ergebnisse zum Gleichungssystem (5)
| n | cond(A) | \( \| \alpha – e^t \|_\infty \) | rel. Fehler |
|---|---|---|---|
| 1 | 5.87 | 1.0 | 36.7 % |
| 2 | 168.03 | 1.0388 | 38.2 % |
| 4 | 910021.07 | 1.08964 | 40.0 % |
| 8 | 7.85e+14 | 4.7194 | 173 % |
| 16 | 7.87e+17 | 108.34 | 3985 % |
| 32 | 2.79e+19 | 267.85 | 9853 % |
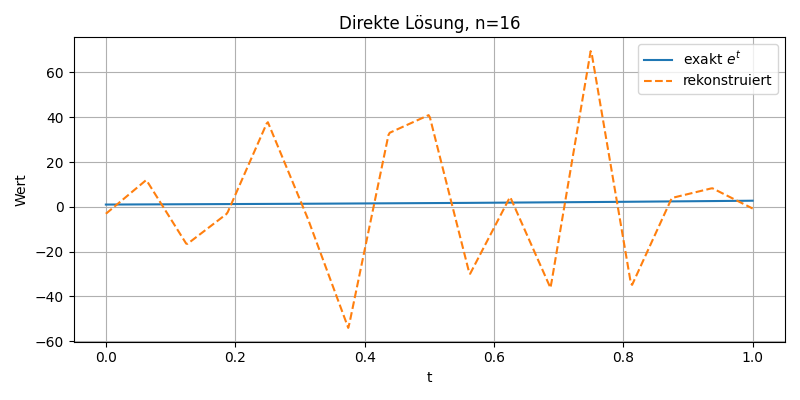
Dieses Diagramm zeigt den Vergleich zwischen der exakten Lösung \( e^t \) (blaue Linie) und der numerisch rekonstruierten Funktion \( \alpha(t) \) (orange gestrichelt) bei direkter Lösung des Gleichungssystems \( \mathbf{A}_n \alpha = y \) mit \( n = 16 \). Aufgrund der schlechten Kondition der Matrix \( \mathbf{A}_n \) ist das Verfahren instabil: Die rekonstruierten Werte oszillieren stark und weichen erheblich vom exakten Verlauf ab. Das Beispiel illustriert die typische Problematik schlecht gestellter inverser Aufgaben und macht die Notwendigkeit einer Regularisierung deutlich.
Zur Regularisierung
Zur Regularisierung des schlecht gestellten Problems wird die Tikhonov-Regularisierung eingesetzt:
\[
(\beta I + \mathcal{A}^* \mathcal{A}) \,\lambda = \mathcal{A}^* y \tag{6}
\]
Dabei bezeichnet \( \mathcal{A}^* \) die adjungierte Abbildung des Operators \( \mathcal{A} \). Sie ist definiert durch die Bedingung:
\[
\langle \mathcal{A} \lambda, y \rangle = \langle \lambda, \mathcal{A}^* y \rangle
\quad\text{für alle } \lambda, y \in L^2(0,1).
\]
Wenn man die Definition von \( \mathcal{A} \) einsetzt, ergibt sich durch Vertauschen der Integrale (Fubini):
\[
(\mathcal{A}^* y)(s) = \int_0^1 e^{t\,s}\,y(t)\,\mathrm{d}t. \tag{7}
\]
Da die Darstellung von \( \mathcal{A}^* \) formal genau der von \( \mathcal{A} \) entspricht (bis auf die Benennung der Integrationsvariable), ist die Aufgabe selbstadjungiert, d.h. \( \mathcal{A}^* = \mathcal{A} \).
Bei der Diskretisierung mit der Trapezregel sind die Randgewichte halbiert, sodass die entstehende Matrix \( \mathbf{A}_n \) nicht symmetrisch ist. Folglich ist die Annahme \( \mathbf{A}_n^* = \mathbf{A}_n^T \) falsch und führt zu Fehlern. Korrekt ist vielmehr, die adjungierte Abbildung ebenso mit der Trapezregel zu diskretisieren, wodurch \( \mathbf{A}_n^* = \mathbf{A}_n \) gilt.
Diskretes Regularisierungssystem (konsistent)
Mit der korrekten adjungierten Matrix \(A_n^* = A_n\) lautet die diskrete Tikhonov-Gleichung
\[
\bigl(\beta\,\mathbf{I} + \mathbf{A}_n\,\mathbf{A}_n\bigr)\,\boldsymbol{\alpha}_\beta
\;=\;\mathbf{A}_n\,\mathbf{y}.
\tag{8a}
\]
Regularisierte Lösung gemäß Gleichung (8a), \( \beta = 10^{-3} \)
| n | \( \| \alpha – e^t \|_\infty \) | rel. Fehler |
|---|---|---|
| 1 | 0.99 | 36.6 % |
| 2 | 0.60 | 22.0 % |
| 4 | 0.234 | 8.6 % |
| 8 | 0.1 | 3.6 % |
| 16 | 0.063 | 2.3 % |
| 32 | 0.054 | 1.9 % |
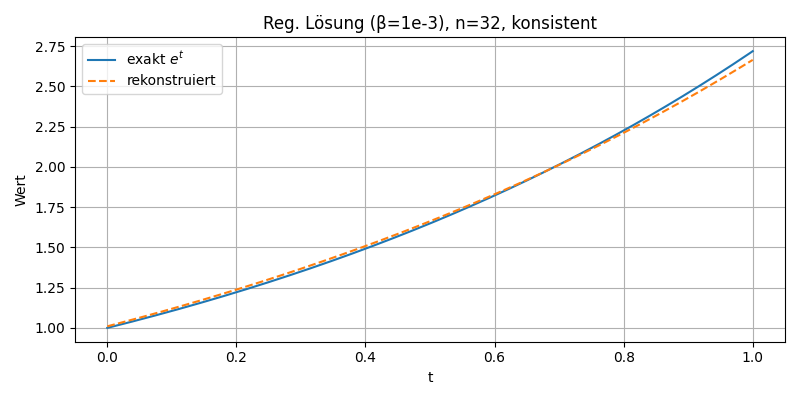
Der Plot zeigt den Vergleich zwischen der exakten Lösung \( e^t \) (blaue Linie) und der numerisch rekonstruierten Funktion (orange gestrichelt) für \( n = 32 \) mit Tikhonov-Regularisierung bei konsistenter Diskretisierung der adjungierten Matrix. Die Annäherung ist bereits recht gut; der maximale Fehler beträgt etwa 2.3 %. Für eine höhere Genauigkeit – etwa unter 0.1 % – müsste \( n \) weiter erhöht (z. B. auf \( n = 128 \)) und der Regularisierungsparameter auf \( \beta = 10^{-6} \) reduziert werden.
Gleichung (8a), \( \beta = 10^{-6} \)
| n | \( \| \alpha – e^t \|_\infty \) | rel. Fehler |
|---|---|---|
| 1 | 1.0 | 36.7 % |
| 2 | 1.0335 | 38.0 % |
| 4 | 0.5639 | 20.7 % |
| 8 | 0.202 | 7.4 % |
| 16 | 0.057 | 2.12 % |
| 32 | 0.016 | 0.6 % |
| 128 | 0.0029 | 0.10 % |
Diskretes Regularisierungssystem (inkonsistent)
Setzt man fälschlich \(A_n^* = A_n^T\), erhält man stattdessen
\[
\bigl(\beta\,\mathbf{I} + \mathbf{A}_n^T\,\mathbf{A}_n\bigr)\,\boldsymbol{\alpha}_\beta
\;=\;\mathbf{A}_n^T\,\mathbf{y}.
\tag{8b}
\]
Effekt einer nicht-konsistenten Diskretisierung (Gleichung (8b))
| n | \( \| \alpha – e^t \|_\infty \) | rel. Fehler |
|---|---|---|
| 1 | 0.99 | 36.6 % |
| 2 | 0.96 | 35 % |
| 4 | 1.0339 | 38 % |
| 8 | 1.19 | 43.9 % |
| 16 | 1.28 | 47.4 % |
| 32 | 1.3371 | 49.18 % |
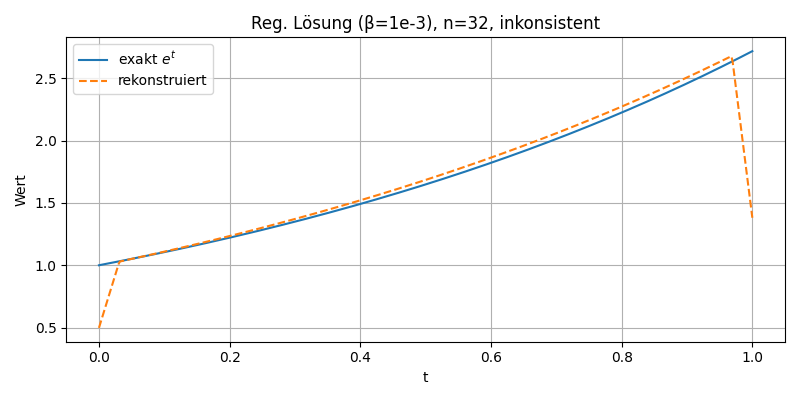
In dieser Darstellung wird die exakte Lösung \( e^t \) (blau) der rekonstruierten Funktion (orange gestrichelt) gegenübergestellt, wobei die Tikhonov-Regularisierung mit inkonsistenter Diskretisierung der adjungierten Matrix verwendet wurde. Trotz Regularisierung zeigen sich deutliche Abweichungen am Rand. Dies unterstreicht die Bedeutung einer konsistenten Diskretisierung bei der Parameteridentifikation.
Zusammenfassung
- Die direkte Lösung des Gleichungssystems (5) ist numerisch instabil. Die Matrix \( \mathbf{A}_n \) ist schlecht konditioniert, was bei wachsendem \( n \) zu stark fehlerhaften Lösungen führt.
- Die Tikhonov-Regularisierung gemäß Modell (8a) stabilisiert das Problem erfolgreich. In Abhängigkeit vom Regularisierungsparameter \( \beta \) und der Diskretisierung \( n \) lässt sich die exakte Parameterfunktion \( \lambda(t) = e^t \) mit hoher Genauigkeit rekonstruieren.
- Eine konsistente Diskretisierung der adjungierten Abbildung \( \mathcal{A}^* \) ist entscheidend. Wird stattdessen fälschlich die transponierte Matrix \( \mathbf{A}_n^T \) verwendet (Modell (8b)), bleibt die Lösung zwar beschränkt, konvergiert jedoch nicht gegen die exakte Funktion \( e^t \).
Sage-Skript
Das Sage-Skript führt die numerische Untersuchung des Modellproblems Parameteridentifikation mit Tikhonov-Regularisierung automatisiert durch. Es erledigt dabei folgende Schritte:
-
Aufbau der Diskretisierungsmatrix \(A_n\)
Verwendung der summierten Trapezregel auf \([0,1]\) mit \(n+1\) Stützstellen;
Bildung der Matrixeinträge \(a_{ij}=w_j\,e^{x_i x_j}\). -
Berechnung der Konditionszahl
Bestimmung der größten und kleinsten Singulärwerte mittels NumPy;
Kennzahl \(\kappa(A_n)=\sigma_{\max}/\sigma_{\min}\). -
Direkte Lösung
Lösung des linearen Systems \(A_n\,\alpha=y\) für \(\alpha\);
Berechnung des absoluten und relativen Fehlers gegenüber \(\lambda(t)=e^t\). -
Tikhonov-Regularisierung
Lösen von \((\beta I + A_n^*A_n)\,\alpha_\beta = A_n^*y\) mit
konsistent: \(A_n^*=A_n\)
inkonsistent: \(A_n^*=A_n^T\)
Vergleich der Regularisierungsergebnisse für \(\beta=10^{-3}\) (Modell 1) und \(\beta=10^{-6}\) (Modell 2). -
Ausgabe
Fünf einheitliche Tabellen im ASCII-Format:- Direkte Lösung (ohne Regularisierung)
- Modell 1 (konsistent / inkonsistent)
- Modell 2 (konsistent / inkonsistent)
Quellen
- (1988): Inverse Problems. In: Hoffmann, K. H.; Hoppe, R. H. W. (Hrsg.): Trends in Mathematical Optimization, S. 117–137, Birkhäuser, Basel, 1988.
Erstellt von Dr. Frank Liebau, Erstfassung: 17. März 2001. Übersetzt in modernes HTML/MathJax 2025.