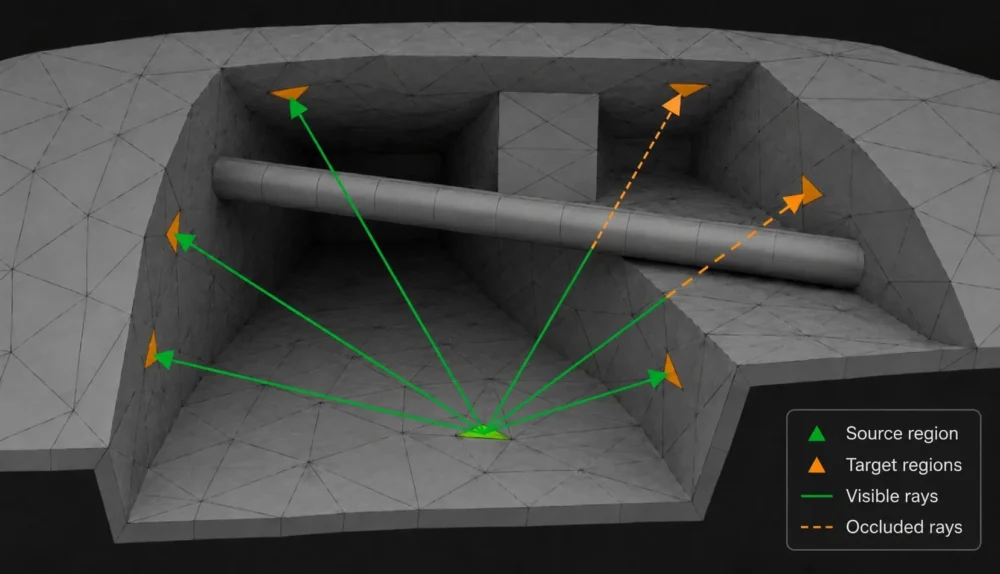
Die Modellierung des Energietransports durch Strahlung mithilfe eines mathematischen Modells erfordert notwendigerweise die Bestimmung der Sichtbarkeiten. D. h. es ist die Frage zu klären, ob ein Punkt auf der Oberfläche des Modells im „Schatten“ eines Strahlers liegt oder nicht. Diese einfache Frage erweist sich als überaus rechenintensiv. Der Einsatz moderner Hardware, insbesondere von GPUs, kann hierbei die Rechenzeiten stark verkürzen.
Bis Mitte der 2000er Jahre steuerten Grafikkarten ausschließlich den Monitor an. Mit dem ersten CUDA-Release Anfang 2007 folgte auch hier eine erstaunliche Entwicklung: der Prozessor der Grafikkarte (Graphics Processing Unit oder kurz GPU) kann nun spezielle Programme ausführen, so dass dieser als “Recheneinheit” neben der CPU zum Einsatz kommt. Die Entwicklung ist hier soweit fortgeschritten, dass High-End-Grafikkarten heute, für bestimmte Anwendungen, auf dem Niveau früherer Supercomputer rechnen. So veröffentlicht Nvidia eine Leistung von 34 TeraFLOPS bei doppelter und 67 TFlops bei einfacher Genauigkeit für das aktuelle GPU-Spitzenmodell Hopper H200. Der effiziente Einsatz von GPUs erfordert angepasste Algorithmen, die auf die massiv parallele Architektur der Grafikkarten abgestimmt sind.
Sichtbarkeitsproblem
Die Sichtbarkeiten eines Dreiecks einer Triangulierung sind alle Dreiecksindizes, die die Definition der Sichtbarkeitsfunktion erfüllen. Für eine naive Auswertung der Definition liegt der Speicherplatzverbrauch in der Größenordnung \(\mathcal{O}(n^2/2)\). Das bedeutet für ein realistisches Beispiel mit 4 Millionen Dreiecken einen möglichen Arbeitsspeicherbedarf von ca. 29 TB, und das allein für die Sichtbarkeiten. Die Formfaktormatrix ist hier noch nicht berücksichtigt.
Die Problemstellung hat aber auch eine positive Eigenschaft: die Aufgabe ist trivial parallelisierbar. Das ist leicht einzusehen, denn die Ergebnisse der Sichtbarkeitsberechnung für ein Dreieck sind völlig unabhängig von anderen Rechenergebnissen. Nur die geometrische Lage der Dreiecke zueinander ist entscheidend. Diese Trivialparallelisierbarkeit eignet sich besonders gut für massiv parallele Hardware wie die GPU.
Um die Anforderung bzgl. Speicherplatz und Rechenzeit zu bewältigen, setzen wir gezielte Optimierungsstrategien ein. Dazu gehören die Nutzung effizienter Datenstrukturen, clusterbasierter Ansätze und spezialisierter Algorithmen, um den Speicherplatzbedarf erheblich zu reduzieren. Ein weiterer Beitrag dazu ist die Verwendung von Nvidias OptiX-Bibliothek. Nvidia-OptiX ist auf schnelle Ray-Tracing-Algorithmen spezialisiert und für die GPU optimiert. Das ist genau die Funktionalität, die wir für den Sichtbarkeitstest benötigen.
Wir haben neben der Cuda-Variante für die GPU auch eine spezielle Version für Intel Embree (Version 3) entwickelt, die jedoch ausschließlich auf der CPU läuft.
Zukünftige Entwicklung
Ab Version 4 unterstützt Embree zusätzlich eine SYCL-basierte Programmierung. SYCL ist ein von Khronos standardisierter C++-Ansatz für heterogene „Single Source“-Programmierung. Dadurch lassen sich Host- und Device-Code in einer gemeinsamen Sprachbasis entwickeln, was die Wartbarkeit und Portierbarkeit komplexer Raytracing-Anwendungen verbessern kann. Für Embree bedeutet das vor allem, dass neben dem klassischen, hochperformanten CPU-Einsatz auch hardwarebeschleunigtes Raytracing auf unterstützten Intel-GPUs möglich wird. Die SYCL-Erweiterung ergänzt damit die bestehende Embree-API um eine moderne C++-basierte Offload-Variante. Sie ist jedoch nicht als vollständig automatische Ausführung auf beliebigen CPU- und GPU-Plattformen zu verstehen, sondern im Rahmen der konkret unterstützten Zielarchitekturen.
Update 2026: Sichtbarkeitsberechnung mit OptiX-7 auf RTX 3080
Die in der ursprünglichen Fassung genannten Einschränkungen für Messungen auf moderner NVIDIA-Hardware sind inzwischen behoben. Die Sichtbarkeitsberechnung wurde mit einem OptiX-7-Backend auf einer RTX 3080 erfolgreich durchgeführt und mit aktuellen Embree-4-Läufen auf der Workstation verglichen (Messstand: 31.03.2026). Wichtig für die Einordnung: Embree-4 nutzt in diesem Setup ausschließlich die CPU, während OptiX-7 die NVIDIA-GPU (RTX 3080) verwendet.
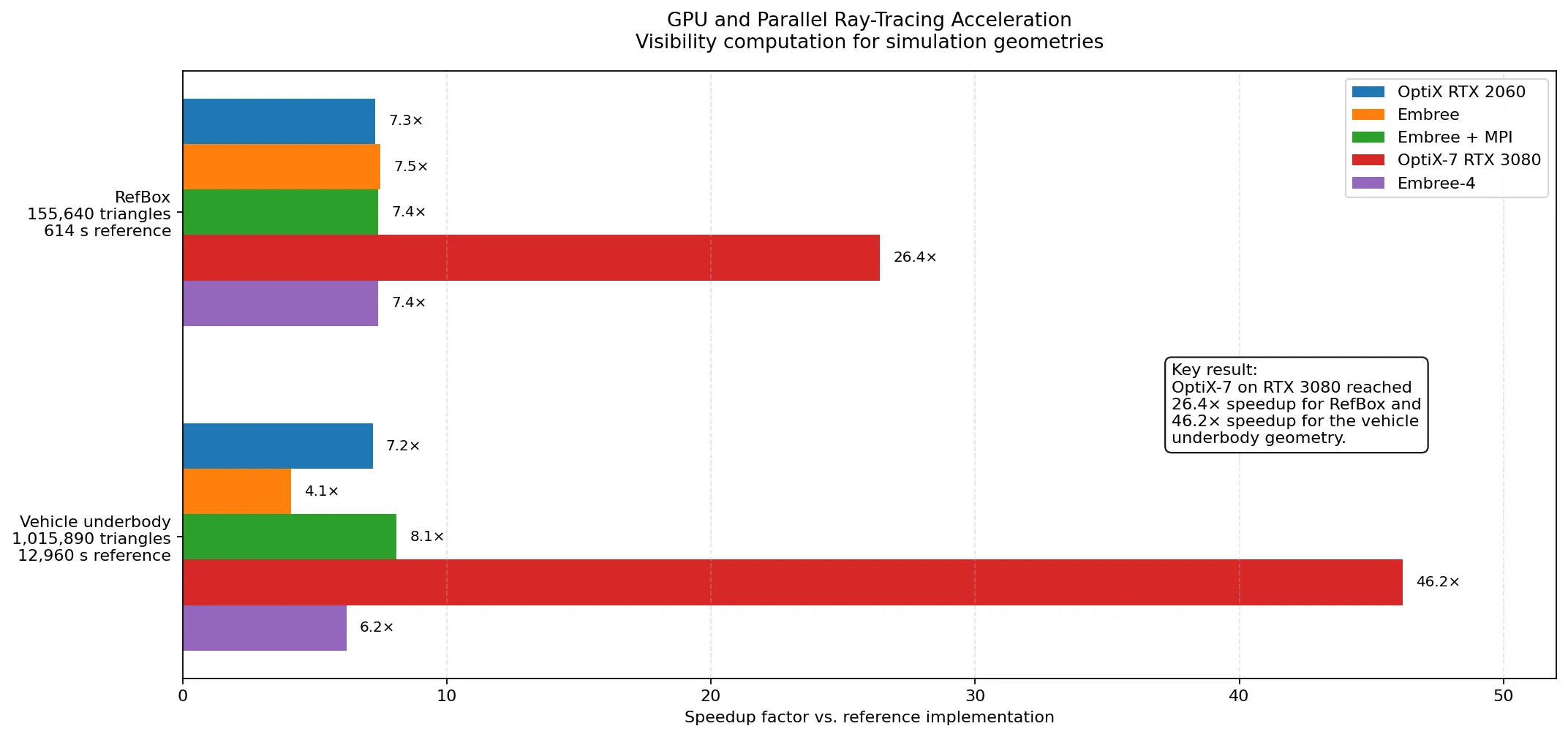
Ergänzte Vergleichstabelle
| RefBox | Greenhouse | Unterboden | Gesamtfahrzeug | |
|---|---|---|---|---|
| Anzahl Dreiecke | 155640 | 709042 | 1015890 | 4691854 |
| host | Workstation | Workstation | Workstation | Cluster |
| Referenzzeit [s] | 614.2 | 20549 | 12960 | 20845 |
| Speedup OptiX (RTX 2060) | 7.3 | 7.5 | 7.2 | – |
| Speedup Embree | 7.5 | – | 4.1 | – |
| Speedup Embree + MPI | 7.4 | 8.9 | 8.1 | 11.1 |
| Speedup OptiX-7 (RTX 3080) | 22.8 | 32.9 | 46.2 | – |
| Speedup Embree-4 | 7.4 | 3.0 | 6.2 | – |
Einordnung
Die GPU-Variante mit OptiX-7 skaliert auf größeren Modellen sehr deutlich und liefert gegenüber der Referenz eine massive Beschleunigung. Beim RefBox-Fall liegt Embree-4 ungefähr auf dem Niveau der bisherigen Embree-Werte; der Hauptsprung kommt hier klar durch das OptiX-7-Backend auf RTX 3080.