Die C++ Standard-Klassen std::set und std::map bzw. ihre unsortierten Varianten
std::unordered_set und std::unordered_map (assoziative Container) sind nicht thread-safe. Eine thread-safe Alternative sind die entsprechenden Container (tbb::concurrent_set, tbb::concurrent_unordered_set, …) aus der frei verfügbaren Intel-Bibliothek Threading Building Blocks (TBB).
Dazu ein Beispiel: für eine FEM-Berechnung sei ein 3D-Modells mittels Tetraeder trianguliert. Üblicherweise wird das Gitter durch eine Liste mit den 3D-Punkten
0 -0.3420 0.3420 0.0020 1 -0.3420 -0.3420 0.0020 2 -0.3420 0.3420 0.6339 3 -0.3420 -0.3420 0.6339 ...
und einer zweiten Liste für die Tetraeder mit Punktindizes
0 524 51485 523 104970 1 104887 52572 120512 120102 2 89182 9528 104369 104369 3 168514 166744 84550 168926 ...
gegeben. In diesem Beispiel definiert das Dreieck zu den Punkten 524, 51485 und 523 zusammen mit dem vierten Punkt zum Index 104970 Tetraeder 0.
Dementsprechend enthält die C++-Klasse der Tetraeder auch diese vier Indizes:
class Tetra
{
public:
array<int,4> v; // Indizes der Knoten
...
}
...
vector<Tetra> Cells;
Zur Aufstellung des Gleichungssystems ist es zweckmäßig, auch die “umgekehrte” Information zu kennen: Zu welchen Tetraedern gehört ein bestimmter Punkt? Dazu sei
typedef std::set<int> IntSet; vector<IntSet> VertexStar(Points.size());
D.h. zu jedem Punkt gibt es eine Menge, die die Indizes der umgebenen Tetraeder enthält. Ein einfacher for-loop über alle Cells liefert das Gewünschte.
Serielles Verfahren
const uint n = Cells.size();
//--------------- Algorithmus-1 -----------------------------
for(uint i=0; i < n; ++i) {
const auto u = Cells[i].v; // Indizes der Punkte zu Cell i
VertexStar[ u[0] ].insert(i); // cell-Index i --> VertexStar[ u[0] ]
VertexStar[ u[1] ].insert(i);
VertexStar[ u[2] ].insert(i);
VertexStar[ u[3] ].insert(i);
};
Wendet man Algorithmus-1 auf ein real-world Beispiel
+----------------------------------------------------------+ | tetra-mesh information | +----------------------------------------------------------+ | Tetraeder-Cells 5721840 | Points 1103378 | map of connected sets is empty
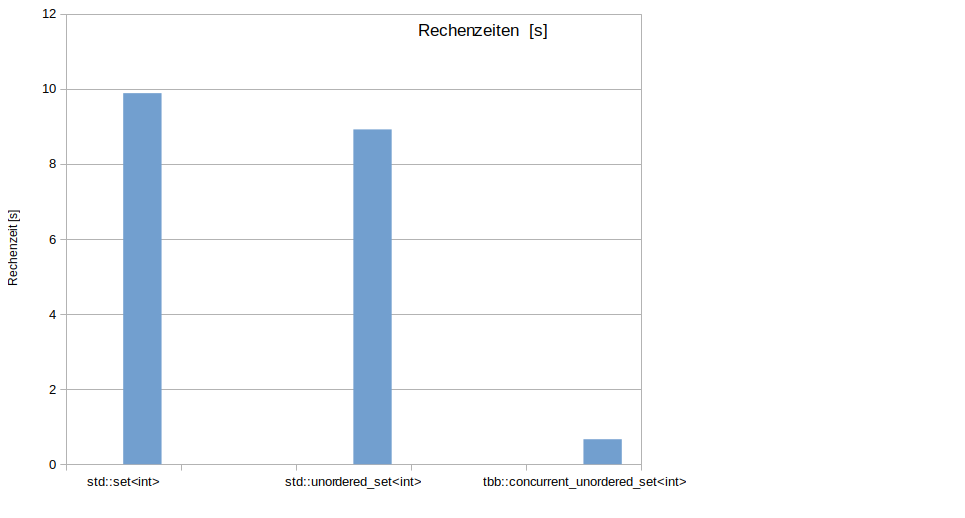
mit 5.7 Mio Elementen an, so beträgt die Rechenzeit 9.88 s.
Eine kleine Verbesserung ergibt sich, wenn auf eine Sortierung der Menge verzichtet wird. Statt std::set<int> kann std::unordered_set<int> verwendet werden, denn nur die Indizes der beteiligten Tetraeder sind interessant. Eine Reihenfolge ist hier nicht wichtig. Die Rechenzeit reduziert sich auf 8.92 s.
OpenMp-Parallelisierung
Der Versuch die for-Schleife mittels OpenMp zu parallelisieren
//--------------- Algorithmus-2 -----------------------------
#pragma omp parallel for
for(uint i=0; i < n; ++i) {
const auto u = Cells[i].v; // Indizes der Punkte zu Cell i
VertexStar[ u[0] ].insert(i); // i --> VertexStar[ u[0] ]
VertexStar[ u[1] ].insert(i);
VertexStar[ u[2] ].insert(i);
VertexStar[ u[3] ].insert(i);
};
endet mit einem Absturz
| Tetra4Mesh::SetSparseMatrixPattern() Speicherzugriffsfehler (Speicherabzug geschrieben)
Das Einfügen einer Zahl in die Menge std::set<int> ist nicht thread-safe. Die Barriere #pragma omp critical(Insert) vor jedem insert-Aufruf “rettet” zwar den Algorithmus-2, bringt aber keinen Fortschritt bzgl. der Rechenzeit, da dann faktisch wieder Verfahren 1 vorliegt.
Parallelisierung mit tbb
Jetzt wird std::set<int> durch tbb::concurrent_unordered_set<int> ersetzt und die for-Schleife mittels tbb::parallel_for parallelisiert.
#include "tbb.h"
...
//--------------- Algorithmus-3 -----------------------------
typedef tbb::concurrent_unordered_set<int> IntSet;
vector<IntSet> VertexStar(Points.size());
tbb::parallel_for(static_cast<uint> (0), n, [&](uint i) {
const auto u = Cells[i].v;
VertexStar[ u[0] ].insert(i);
VertexStar[ u[1] ].insert(i);
VertexStar[ u[2] ].insert(i);
VertexStar[ u[3] ].insert(i);
});
Der insert-Aufruf ist nun thread-safe und die Variante nutzt alle 16 Kerne der CPU. Die Rechenzeit beträgt nur noch erstauliche 0.6562 s. Das ist ein Speedup von 15 (!) und eine fast perfekte Skalierung.
Alle Rechnungen wurden auf einem AMD Ryzen 9 5950X (16 cores) durchgeführt.
Links zu dem Thema:
- Is std::map insert thread safe?
- Pro TBB C++ Parallel Programming with Threading Building Blocks
- C++ Core Guidelines: Teilen von Daten zwischen Threads