Die GIS-basierte Flächensuche ist in vielen Projekten ein entscheidender Zeitfaktor und spielt in sehr unterschiedlichen Kontexten eine Rolle, von Infrastruktur- und Gewerbeentwicklungen bis hin zu Umwelt- und Fachplanungen. Eine automatisierte, datengetriebene Flächenanalyse kann hier ansetzen: Sie identifiziert in kurzer Zeit Kandidatenflächen, schließt offensichtlich ungeeignete Bereiche aus und beschleunigt die Vorprüfung deutlich.

Kernidee: Für ein definiertes Untersuchungsgebiet (AOI), ein PLZ-Gebiet, ein Landkreis oder ein Bundesland, werden alle Höhenmodell-Kacheln verarbeitet, die dieses Gebiet schneiden (siehe Datenbasis). Die Kachel ist die Verarbeitungseinheit, und die Pipeline läuft automatisiert über die vollständige Kachelmenge des AOI.
Methodisch ist das zugleich ein gutes Beispiel dafür, wie Mathematik, Numerik und Geometrie in praktische Entscheidungsprozesse einfließen. Häufig liegt das digitale Geländemodell als Rasterdatensatz vor, zum Beispiel als GeoTIFF-Datei. Daraus lassen sich topografische Kenngrößen numerisch ableiten, mit Finite-Differenzen-Approximationen für lokale Ableitungen und mit Interpolation für konsistente Werteübergänge. Daneben existieren Höhenmodelle, die direkt auf Punktwolken basieren, wie bei LiDAR-Aufnahmen. In solchen Fällen spielen Triangulierungen, insbesondere Delaunay-Triangulationen, eine zentrale Rolle. Dieses Konzept ist auch aus FEM sowie aus verwandten Verfahren wie Box- bzw. Finite-Volumen-Methoden gut bekannt. Im nächsten Schritt entsteht die eigentliche Flächenabgrenzung. Geeignete Bereiche werden zu zusammenhängenden Regionen zusammengefasst und als Polygone aufbereitet. Dabei sind Methoden der algorithmischen Geometrie für Komponentenbildung, Verschneidung, Bereinigung und Vereinfachung zentral.
Damit diese Kette auch bei großen Gebieten funktioniert, ist Skalierung entscheidend. Für die Vektordaten hat sich GeoPackage (GPKG) als robustes Arbeitsformat bewährt, denn mit einem räumlichen Index (R-Tree) lassen sich Filter und Überlagerungen auch bei großen Layern effizient ausführen. PostGIS kann als Staging-Schicht für performante Overlay- und Distanzoperationen dienen. So lassen sich Kandidatenflächen effizient ableiten, bewerten und für nachgelagerte GIS-Workflows exportieren.
Datenbasis
Ein digitales Geländemodell (DGM) beschreibt die Bodenhöhe ohne Gebäude und Vegetation, ein digitales Oberflächenmodell (DOM/DSM) enthält zusätzlich Bebauung und Bewuchs. Zur Vereinfachung wird im Folgenden „DEM“ (Digital Elevation Model) als Sammelbegriff für kachelweise bereitgestellte Höhenmodelle verwendet, also sowohl DGM (Bodenmodell) als auch DOM/DSM (Oberflächenmodell).
Das Vorgehen stützt sich auf zwei zentrale Datenquellen.
- Höhendaten als Raster (GeoTIFF) und je nach Datenangebot auch als Punktwolke (z. B. LiDAR). Typischerweise liegen DEM-Kacheln als 1 km × 1 km bei 1 m Auflösung vor, z. B. in EPSG:25832. Aus den Höhendaten lassen sich topografische Kenngrößen ableiten, die für die Flächenbewertung zentral sind.
- Vektordaten für Ausschlussmasken aus OpenStreetMap (OSM), z. B. Wasserflächen und Wald. Diese Informationen dienen als Ausschlusskriterien; optional können vorhandene WFS-Layer (z. B. regionale Fachportale) ergänzt werden.
Die offenen Geobasis-Portale der Bundesländer liefern die Datenbasis. Eine landesspezifische JSON-Konfiguration beschreibt Einstiegspunkte und Download-Parameter, weil Struktur, Metadaten und Zugriffswege je Bundesland variieren. Ein Python-Downloader liest die Konfigurationen, lädt die DEM-Kacheln und legt sie in einer konsistenten Projektstruktur ab. Optional schreibt er ein Manifest (Datenstand, Parameter, heruntergeladene Dateien) und protokolliert Vollständigkeits- und Integritätsprüfungen (z. B. Dateigröße/Hash). Bei temporären Netzwerkproblemen startet der Downloader Wiederholversuche (Retries).
Die Kachelstruktur vereinfacht den Download und beschleunigt die spätere Verarbeitung. Kachelbasierte Workflows skalieren gut, und räumliche Indexstrukturen wie Quadtrees helfen, Teilgebiete gezielt nachzuladen und Ergebnisse konsistent über Kachelgrenzen hinweg zusammenzuführen.
Exemplarisch lässt sich das Vorgehen an Brandenburg erläutern: Der Python-Downloader lädt DEM‑Kacheln automatisiert aus dem GeoBasis‑BB‑Verzeichnis herunter. Bei einer Fläche von rund 30.000 km² fallen bei 1 km × 1 km‑Kacheln ungefähr 30.000 Kacheln an.
Vereinfacht sieht die Kernlogik im Downloader dann so aus:
def download_tile(tile, output_dir, force):
target = output_dir / tile.name
if target.exists() and not force:
return
with urllib.request.urlopen(tile.url) as response, open(target, "wb") as handle:
shutil.copyfileobj(response, handle)
for tile in filtered:
download_tile(tile, args.output, args.force)Als grobe Analogie auf der Kommandozeile entspricht das:
for tile in 33250-5888 33250-5889; do
curl -L -o "dgm_${tile}.zip" "https://data.geobasis-bb.de/geobasis/daten/dgm/xyz/dgm_${tile}.zip"
doneWorkflow in 4 Schritten
Ziel ist es, aus Raster- und Vektordaten priorisierte Polygonflächen abzuleiten, die direkt im GIS geprüft und weiterverarbeitet werden können. Die Methodik ist dabei bewusst allgemein gehalten und lässt sich auf unterschiedliche Planungs- und Prüfkontexte übertragen.
1) Ableitungen aus dem Digitalen Gelaendemodell
Welche Kenngrößen tatsächlich verwendet werden, hängt vom Anwendungsfall ab. Im Folgenden dienen Steigung und Südausrichtung nur als Beispiel, weil sie leicht zu interpretieren sind und sich gut zur Illustration der Maskenbildung eignen.
Je nach Bundesland liefern die Geodatenportale das Digitale Geländemodell in unterschiedlichen Formaten. In Brandenburg stellen sie die Daten auch als XYZ-Punktwolken bereit. Der Konverter rasterisiert diese Punktwolken in ein einheitliches GeoTIFF (typisch 1 m Auflösung). Optional erzeugt der Prozess zusätzlich ein ParaView-kompatibles Format für die 3D-Visualisierung. Anschließend berechnet das System aus dem Raster Kenngrößen wie Neigung, Rauigkeit und Südausrichtung.

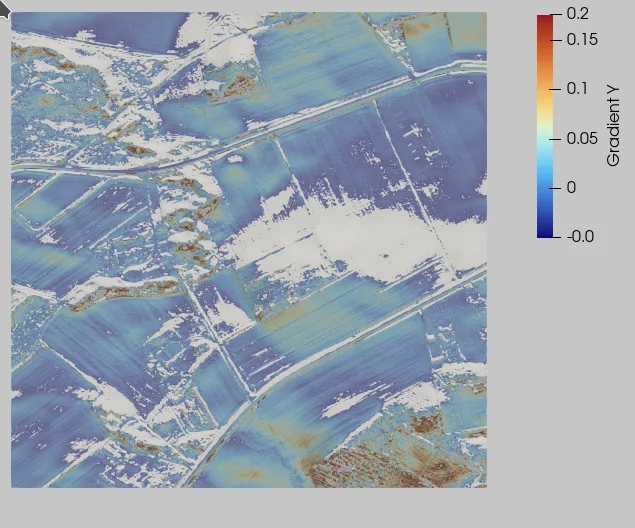
Vereinfacht lassen sich die beiden Beispielkriterien so formulieren:
-
Ebene Fläche (kleine Hangneigung):
\[ \qquad \qquad
\lVert \nabla h \rVert < \varepsilon \] -
Südausrichtung (passende Exposition):
\[ \qquad \qquad
\left\langle \frac{-\nabla h}{\lVert \nabla h \rVert}, \mathbf{e}_{\mathrm{south}} \right\rangle > \mathrm{tol}
\qquad \textsf{ (Variante Gradient)}
\]\[ \qquad \qquad
\mathbf{n} = (-\partial_x h,\,-\partial_y h,\,1), \qquad
\left\langle \frac{\mathbf{n}}{\lVert \mathbf{n} \rVert}, \mathbf{e}_{\mathrm{south,3D}} \right\rangle > \mathrm{tol}
\qquad \textsf{(Variante Flächennormale)}
\]
Dabei bezeichnet \(h(x,y)\) das Höhenfeld (Geländehöhe) über der \(xy\)-Ebene und \( \nabla h = (\partial_x h,\partial_y h) \) den lokalen Steigungsvektor (Gradienten). Der Betrag \( \|\nabla h\| \) ist ein Maß für die Hangneigung, und \( \varepsilon \) ist der zugehörige Schwellwert. Für die Südausrichtung gibt es zwei äquivalente Sichtweisen: Über die Richtung der stärksten Abnahme (mit \(-\nabla h\)) oder über die Flächennormale \( \mathbf{n} \). In beiden Fällen wird die lokale Richtung mit einer Zielrichtung verglichen (z. B. Süden). Über das Skalarprodukt wird geprüft, ob die lokale Richtung ausreichend gut zur Zielrichtung passt. Die Schwelle \(\mathrm{tol}\) steuert, wie streng diese Ausrichtung gefordert wird.
2) Ausschlussmasken anwenden
Aus den abgeleiteten Kenngrößen wird eine Eignungsmaske gebildet, typischerweise über Schwellwerte, für geringe Neigung (hinreichend ebene Bereiche) und eine gewünschte Exposition wie Südausrichtung. Morphologische Operationen wie Opening und Closing glätten bei Bedarf kleine Löcher, Ausreißer und Rauschen. Anschließend wird die Maske mit Ausschluss- und Konfliktdaten überlagert, etwa mit OSM-Wasserflächen oder Wald, sodass diese Bereiche aus der Kandidatenmaske entfernt werden. Im Bild ist das am Beispiel einer Wasserfläche zu sehen, die von der DEM-Kachel abgezogen wird, sodass nur die verbleibenden Landbereiche als Kandidaten übrig bleiben. Zusätzlich können Fachlayer über WFS (Web Feature Service) eingebunden werden, also online bereitgestellte Vektordaten wie Schutzgebiete oder planungsrechtliche Layer.
Praktisch wird das über eine AOI-Bounding-Box und den R-Tree-Index in GeoPackage (GPKG) umgesetzt. Damit lässt sich ein Ausschlusslayer früh räumlich einschränken, sodass nur AOI-Treffer in die Überlagerung eingehen. Bei GeoJSON ist das in der Regel deutlich teurer, weil große Dateien häufig vollständig eingelesen und Feature für Feature geprüft werden müssen. In einem Testlauf sank die Laufzeit für die Ausschlüsse von 344,6 s auf 0,18 s. Das entspricht einem Speed-up von fast 2.000×, weil statt 1.077.114 OSM-Straßen-Features nur 303 AOI-Treffer verarbeitet wurden (Bounding-Box-Filter plus R-Tree). Die Gesamtlaufzeit ging dabei von 352,4 s auf 7,9 s zurück (≈ 45×). Das Ergebnis blieb praktisch identisch.
3) Bildung zusammenhaengender Flaechen
Die kombinierte Maske wird komponentenbasiert ausgewertet (4-/8-Konnektivität), in Polygone umgewandelt und anschließend gefiltert. Typische Filter sind Mindestfläche und Kompaktheit. Zur Reduktion der Geometriekomplexität kann zusätzlich eine Vereinfachung eingesetzt werden, zum Beispiel der Douglas-Peucker-Algorithmus. So bleiben zusammenhängende, planerisch relevante Flächen übrig, die als Kandidaten weiter betrachtet werden können.
4) Scoring und Priorisierung
Für jede Polygonfläche berechnet das System Kennwerte, zum Beispiel Fläche, Statistiken zu Neigung und Rauigkeit sowie Konfliktflags. Daraus wird ein nachvollziehbares Scoring gebildet, das eine priorisierte Kandidatenliste ermöglicht. Gewichtungen und Parameter werden dokumentiert und versioniert, sodass Ergebnisse und Rangfolgen reproduzierbar bleiben.
Ergebnisse & Outputs
Alle Ableitungen, Masken, Polygonisierung und Bewertungen werden durch ein Python-Programm erzeugt. Die Ausschlussmasken basieren auf OpenStreetMap-Daten, die als PBF-Extrakt für Brandenburg bezogen und anschließend automatisiert in thematische Layer überführt werden, insbesondere Wasserflächen und -linien, Wald, Feuchtgebiete, Wohngebiete sowie Straßen und Wege. Quelle (Geofabrik): brandenburg-latest.osm.pbf. Die Extraktion erfolgt skriptgesteuert mit GDAL/ogr2ogr und Makefile-Targets.
Die folgenden Ansichten zeigen die resultierenden Layer in QGIS.

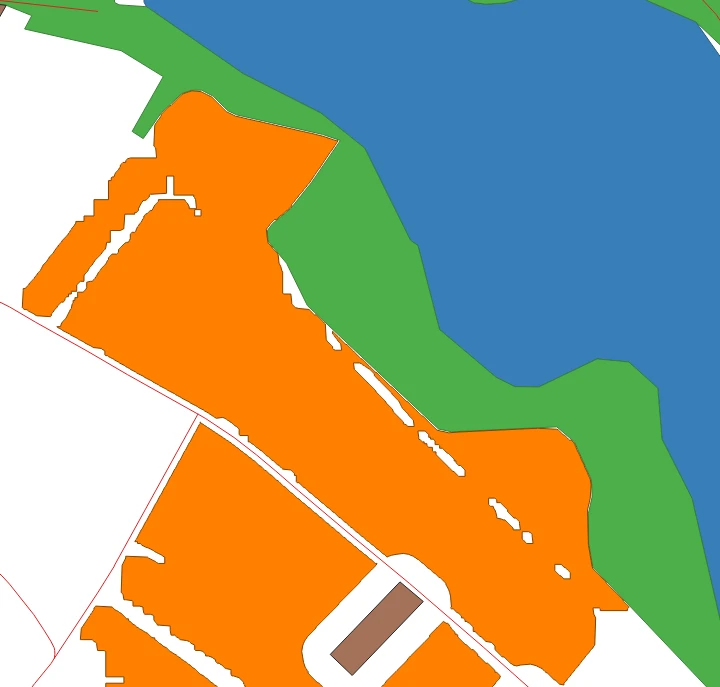
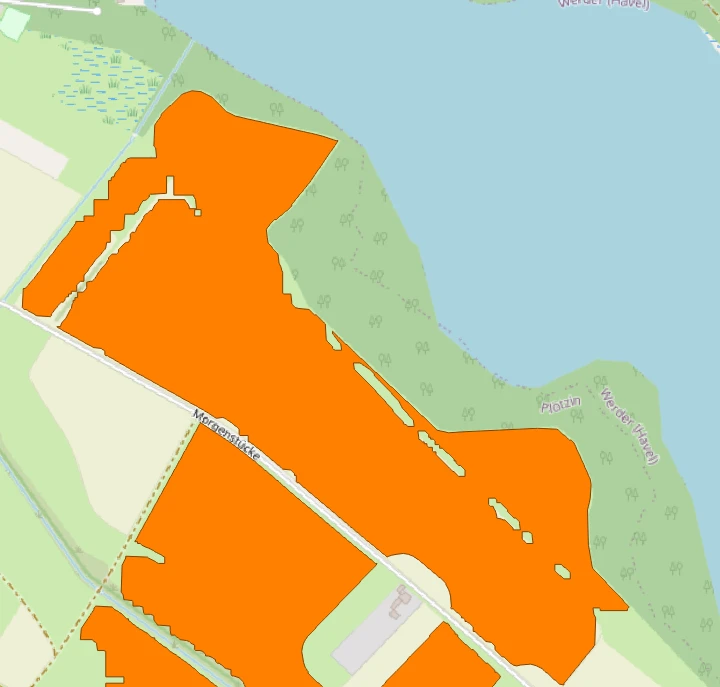
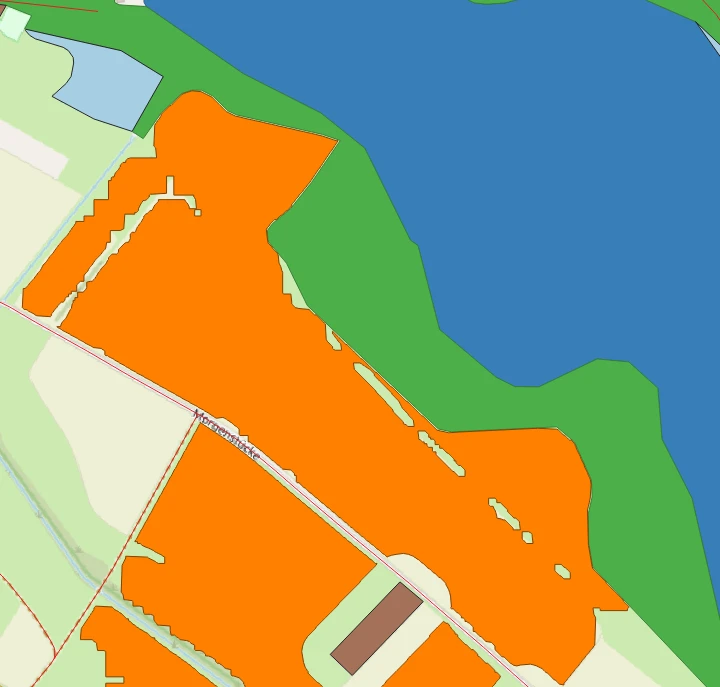
Die Outputs sind so gestaltet, dass sie unmittelbar in gängigen GIS-Werkzeugen genutzt und weiterverarbeitet werden können, besonders in QGIS:
- Kandidatenflächen als Polygonlayer im GeoPackage-Format (GPKG) für die Projektablage. Optional zusätzlich als GeoJSON für Austausch und Web-Workflows.
- Attributtabelle beziehungsweise Topliste als CSV mit den relevanten Bewertungsmerkmalen
- Run-Dokumentation mit AOI, Datenständen, Parametern und Zeitstempel
Damit liegen sowohl eine Karte zur visuellen Prüfung als auch strukturierte Tabellen für Filterung und Priorisierung vor. Die Ergebnisse lassen sich projektübergreifend vergleichen und unabhängig vom konkreten Anwendungsfall in bestehende GIS-Workflows integrieren.
Perspektivisch kann zusätzlich eine leichte, interaktive UI ergänzt werden, etwa auf Basis von Plotly. Denkbar sind Ranking-Ansichten, Filter und Drill-down, Karten-Overlays sowie Parametervergleiche zwischen Runs. So lassen sich Kandidaten auch ohne vollständiges GIS-Setup schnell sichten, während die GIS-Exports weiterhin die maßgeblichen Ergebnisse liefern.
Fazit und Ausblick
Die GIS-basierte Flächensuche lässt sich als durchgängige Pipeline aufsetzen: DGM/DOM einlesen und aufbereiten, daraus Kenngrößen ableiten, Eignungs- und Ausschlussmasken kombinieren, zusammenhängende Bereiche zu Polygonen aggregieren und anschließend filtern und bewerten. So entstehen Kandidatenflächen, die sich in Standard-GIS-Werkzeugen direkt prüfen und weiterbearbeiten lassen. Kachelbasierte Verarbeitung, nachvollziehbare Parameter und saubere Exporte helfen dabei, die Ergebnisse konsistent zu halten und Varianten strukturiert gegenüberzustellen.
Für die nächsten Ausbaustufen bieten sich einige pragmatische Erweiterungen an. Mit PLZ- oder Gemeindepolygonen kann die AOI-Auswahl deutlich komfortabler werden (alle Kacheln, die den Bereich schneiden); alternativ lässt sich ein Gebiet über Gemeinde plus Radius R definieren (alle Kacheln im Umkreis von R km). Zusätzlich können Infrastrukturdatensätze wie Stromnetz-Leitungen und Umspannwerke einfließen. Daraus lassen sich Kennwerte wie die Distanz zum nächsten Netzanschlusspunkt ableiten und in Filter oder Scoring einbauen. Ebenso relevant sind verkehrliche Kriterien, z. B. die Nähe zu Autobahnanschlüssen oder gut ausgebauten Zuwegungen, um Erreichbarkeit und Logistik bereits in der Vorprüfung zu berücksichtigen.
Hinweis: Der Beitrag entstand mit Unterstützung von ChatGPT. Inhaltliche Prüfung, Auswahl und Redaktion liegen beim Autor.