Key words: Scheduling, combinatorial optimization
Ablaufplanung (Scheduling) ist die Optimierung von Reihenfolgen und Ressourcenzuordnungen unter Kapazitätsrestriktionen. Das Beispiel zeigt, wie stark sich makespan und Auslastung durch gute Planung verbessern lassen und nutzt dafür OptaPlanner beziehungsweise Timefold. Details folgen im Abschnitt Solver mit OptaPlanner / Timefold.
Das Problem
Gegeben sei eine Menge von Arbeitsaufträgen und bestimmte Ressourcen mit beschränkter Kapazität. Jeder Auftrag besteht aus einer Anzahl von Aktivitäten (auch Operationen oder Task genannt), die evtl. in einer vorgegebenen Reihenfolge abzuarbeiten sind. Dabei bindet jede Operation bei ihrer Ausführung bestimmte Ressourcen. Gesucht ist ein unter betriebswirtschaftlichen Aspekten möglichst optimaler Ablaufplan.
Ausgehend von einem mathematischen Modell kann die Aufgabe als kombinatorisches Scheduling-Problem formuliert werden. Ein bekanntes Idealmodell dieser Problemfamilie sind Job-Shop-Probleme und ihre Varianten. Für diese Problemklasse ist bekannt, dass sie NP-schwer ist. Damit ist kein polynomialer Algorithmus zu erwarten, der für alle Instanzen optimale Pläne berechnet. In der Praxis sucht man daher in der Regel nicht nach einer garantiert optimalen Lösung, sondern beschränkt sich darauf, zulässige und möglichst gute Lösungen zu finden und diese schrittweise zu verbessern.
Das hier gezeigte Beispiel ist fachlich genauer ein Resource-Constrained Project Scheduling Problem (RCPSP), also eine Projektablaufplanung mit Vorrangrelationen und Kapazitätsrestriktionen bei Minimierung des makespan (Gesamtbearbeitungszeit).
Methodisch liegt die Ablaufplanung damit in der gleichen Familie wie klassische kombinatorische Probleme, bei denen heuristische lokale Suche dominiert. Ein anschauliches Referenzbeispiel ist das Traveling Salesman Problem (TSP).
In logistischen Anwendungen entsprechen Arbeitsaufträge typischerweise Belieferungen oder Versandaufträgen, Aktivitäten einzelnen Prozessschritten wie Kommissionierung, Umschlag oder Verladung und Ressourcen den verfügbaren Kapazitäten in Lager, Personal oder Transport. Das dargestellte Modell ist damit strukturell identisch zu operativen Planungsproblemen in Logistiknetzwerken.
Sehr ähnliche Modelle treten auch bei Zuweisungsproblemen auf. Ein Beispiel ist die Parkplatzzuweisung, bei der Fahrzeuge (Aufträge) Stellplätzen (Ressourcen) zugeordnet werden. Typische Nebenbedingungen sind Kapazitäten, Zeitfenster, Wegezeiten, Prioritäten oder Präferenzen (z. B. Nähe, Ladeinfrastruktur, Reservierungen). Ein weiteres Beispiel ist die Gate- und Standzuweisung am Flughafen, das Airport Gate Assignment Problem (AGAP): Flüge werden zeitabhängig Gates oder Abstellpositionen zugeordnet, typischerweise mit Kompatibilitätsregeln (Flugzeugtyp, Abfertigungsanforderungen) und Konflikten durch zeitliche Überlappungen an derselben Ressource. In der Praxis entstehen daraus häufig kombinierte Zuordnungs- und Ablaufplanungsprobleme, die mit heuristischen Verfahren oder Optimierungsmodellen (z. B. ganzzahliger Optimierung) behandelt werden.
Ein einfaches Beispiel zur Ablaufplanung (Scheduling)
Das folgende Szenario ist ein bewusst vereinfachtes Beispiel und dient der Veranschaulichung der Ablaufplanung.
Ein Logistikteam aus 4 Mitarbeitenden soll drei Versandaufträge (Jobs)
\[J_1 = \{O_1, O_2, O_3, O_4\}, \; J_2 = \{O_5, O_6, O_7\} \; \text{und} \; J_3 = \{O_8, O_9\}\]
so schnell wie möglich abwickeln. Jede einzelne Operation erfordert bestimmte Ressourcen (Mitarbeitende) und eine bestimmte Durchführungsdauer. Gefordert ist dann die Minimierung der Gesamtbearbeitungszeit für die Versandaufträge, der sogenannte makespan.
| Job | j | Aktion | Dauer [min] | MA |
|---|---|---|---|---|
| \(J_1\) | 1 | \(O_1\) | 20 | 1 |
| 2 | \(O_2\) | 40 | 2 | |
| 3 | \(O_3\) | 10 | 1 | |
| 4 | \(O_4\) | 80 | 3 | |
| \(J_2\) | 5 | \(O_5\) | 30 | 2 |
| 6 | \(O_6\) | 20 | 1 | |
| 7 | \(O_7\) | 15 | 3 | |
| \(J_3\) | 8 | \(O_8\) | 60 | 1 |
| 9 | \(O_9\) | 90 | 1 |
Die Aktivitäten sind nicht unabhängig voneinander ausführbar, sondern es muss eine bestimmte Reihenfolge eingehalten werden, die mittels der sogenannten Vorrangrelation gegeben ist. Der nachfolgende Graph (ein gerichteter azyklischer Graph, DAG) definiert die Vorrangrelation für dieses Beispiel. So kann z.B. Operation \(O_3\) erst starten, wenn \(O_2\) (Freigabe) und \(O_5\) (Materialbereitstellung) abgeschlossen sind, während \(O_1\) und \(O_6\) unabhängig voneinander sind.
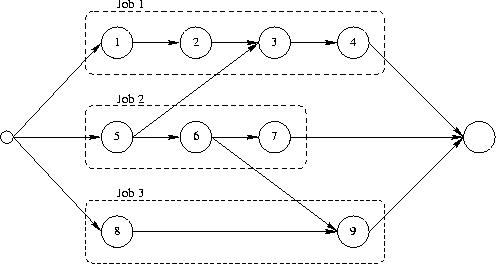
Der makespan (Gesamtbearbeitungszeit) bezeichnet die Fertigstellungszeit des gesamten Plans, also den Zeitpunkt, zu dem die letzte Operation abgeschlossen ist. Ist \(s_i\) die Startzeit und \(p_i\) die Dauer der Operation \(O_i\), dann ist ihre Endzeit \(C_i = s_i + p_i\). Der makespan ergibt sich als
\[
C_{\max} \;=\; \max_i C_i \;=\; \max_i (s_i + p_i).
\]
Im vorliegenden Beispiel wird das Optimierungsziel durch die Endzeiten der Operationen \(O_4\), \(O_7\) und \(O_9\) festgelegt. Damit gilt konkret:
\[
\text{makespan} = \max\{s_4 + 80,\; s_7 + 15,\; s_9 + 90\}.
\]
Auswertung
- Insgesamt gibt es erstaunliche 362880 möglichen Anordnungen der Operationen. Davon sind aber nur 810 zulässige Pläne, d.h. sie erfüllen die Vorrangrelation. Von den 810 zulässigen Plänen wiederum sind nur 10% optimal.
- Unter der Voraussetzung, dass eine Aktivität O begonnen wird, falls
- alle Vorgänger beendet und
- genügend Gruppenmitglieder (Ressourcen) zur Durchführung von O frei sind
ergeben sich die Zeiten und Vergleiche der nachfolgenden Tabelle:
| Plan | makespan [min] | Differenz zu \(S_0\) [min] |
|---|---|---|
| bester Plan \(S_0\) | 170 | – |
| schlechter Plan \(S_B\) | 220 | 50 (23%) |
| Erwartungswert | 184 | 14 (7.6%) |
Gegenüber einem schlechten Plan, dieser sei mit \(S_B\) bezeichnet, bei dem das Team mit 4 Mitgliedern 50 Minuten mehr benötigt, als wenn es nach \(S_0\) vorgeht, ist durch die Optimierung die Leistungsfähigkeit der Gruppe um ca. 23% erhöht worden. Wird aus allen zulässigen Plänen zufällig einer ausgewählt, so ist der Erwartungswert des makespans 184 min. Ein optimaler Plan ist durchschnittlich noch 7.6% besser.
Ressourcenauslastung im Vergleich
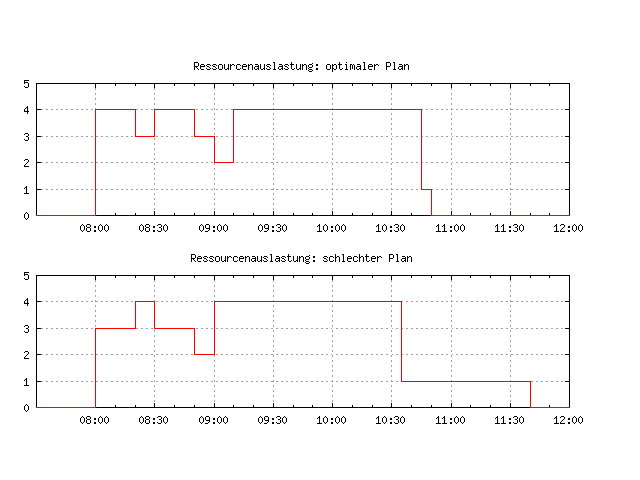
Die beiden nächsten Grafiken zeigen die Ressourcenauslastung bzgl. \(S_0\) und \(S_B\). Man sieht sofort, dass ein Vorgehen nach dem zweiten Plan alles andere als gut ist, was auch an der Einfachheit des Beispiels liegt: die vorgegebene Situation ist noch recht übersichtlich.
Im Fall \(S_0\) werden die Versandaufträge im Zeitraum von 8:00 bis 10:50 vollständig bearbeitet und alle Mitglieder der Gruppe sind durchgehend gut beschäftigt (insgesamt 55 min “Leerlauf”). Während eine Arbeitsorganisation nach \(S_B\) erst um 11:40 fertig ist und immerhin 255 min “Untätigkeit” für die Arbeitsgruppe erzeugt.
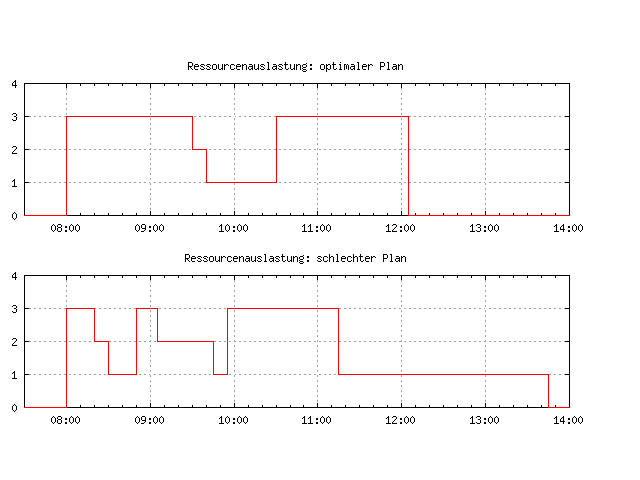
Das Team muss aus mindestens 3 Mitgliedern bestehen, da die Aktivitäten \(O_7\) und \(O_4\) in diesem Beispiel nur von 3 Mitarbeitenden gemeinsam ausgeführt werden können. Wie sehen nun die Ergebnisse für eine Gruppe mit nur 3 Arbeitern aus?
| Plan | makespan [min] | Differenz zu \(S_0\) [min] |
|---|---|---|
| bester Plan \(S_0\) | 245 | – |
| schlechter Plan \(S_B\) | 345 | 100 (29%) |
| Erwartungswert | 284 | 39 (13.7%) |
Das Team mit 3 Mitgliedern benötigt mindestens 245 min zur Bewältigung der Arbeitsaufträge, kann diese aber auch bei schlechter Planung 100 min später abgeschlossen haben, d.h. bzgl. des Optimierungsziels makespan, ist \(S_0\) 29% besser als \(S_B\).
Anmerkung
Für dieses einfache Beispiel ist es übrigens “schwieriger” die schlechten Pläne zu finden. Wählt man aus den 810 zulässigen Plänen zufällig einen aus, so liegen der Erwartungswert für die Bearbeitungszeit der 3 Jobs näher an der eines optimalen Plans, als an den Zeiten für die “schlechten” Pläne. Aber natürlich ist der durch die Optimierung gefundene Plan \(S_0\) einem zufällig ausgewählten Plan überlegen: durchschnittlich hat man eine Effizienzsteigerung um 7.6% bzw. 13.7%.
Solver mit OptaPlanner / Timefold
Das Beispiel lässt sich direkt als kombinatorisches Optimierungsproblem mit OptaPlanner bzw. Timefold Solver modellieren. Dabei handelt es sich um Java-basierte Solver-Frameworks für kombinatorische Optimierung (z. B. Scheduling, Tourenplanung, Zuordnung, Schichtplanung): Man beschreibt Variablen, Regeln/Constraints und Optimierungsziele; der Solver erzeugt und verbessert dann automatisch Lösungen mittels Heuristiken und lokaler Suche. Der hier gezeigte PoC ist in Java (Maven-Projekt, Java 17+) umgesetzt. Timefold Solver ist der aktiv weiterentwickelte Fork von OptaPlanner (u. a. vom OptaPlanner-Erfinder mitgegründet). Für neue Projekte ist Timefold daher oft die naheliegendere Wahl. Zusätzlich hat Red Hat den Red Hat Build of OptaPlanner 8 zum 30. Mai 2024 auf End of Life (EOL) gesetzt (Extended Life Support bis Mai 2026). Hinweise und Links dazu stehen im Abschnitt Weiterlesen.
Kern des Verfahrens
- Modellierung: Jede Operation \(O_i\) ist eine Planning Entity mit diskreter Startzeit im 5-Minuten-Raster (time grains).
- Hard Constraints: Vorrangrelation (DAG) und Kapazität (Summe der gebundenen Mitarbeitenden je Zeitscheibe \(\le\) Kapazität).
- Soft Objective: Minimierung des makespan.
- Suche: Construction Heuristic + Local Search; zusätzlich zu Standard-Änderungsmoves werden problemnahe Reschedule-Moves verwendet (lokale Reihenfolgeänderung + erneute serielle Einplanung).
- PoC-Seed: Start mit einer zulässigen, aber nicht optimalen seriellen Einplanung; die Heuristik verbessert diese anschließend (z. B. von 305 auf 245 min im 3-MA-Fall).
Wichtige Stellen im Code (PoC)
1) Planning Entity / Planning Variable (Operation mit Startzeit als Variable):
@PlanningEntity
public class Operation {
@PlanningId
private String id;
@PlanningVariable(valueRangeProviderRefs = "timeGrainRange")
private TimeGrain startGrain;
private int durationMinutes;
private int durationGrains;
private int demand;
}
2) Constraints (DAG + Kapazität + makespan):
public class JobShopConstraintProvider implements ConstraintProvider {
@Override
public Constraint[] defineConstraints(ConstraintFactory factory) {
return new Constraint[] {
precedence(factory),
capacity(factory),
makespan(factory)
};
}
private Constraint precedence(ConstraintFactory factory) { ... } // start(B) >= end(A)
private Constraint capacity(ConstraintFactory factory) { ... } // Summe demand je Grain <= capacity
private Constraint makespan(ConstraintFactory factory) { ... } // max(endMinute) minimieren
}
3) Solver-Aufruf (Timefold / Java):
import ai.timefold.solver.core.api.solver.Solver;
import ai.timefold.solver.core.api.solver.SolverFactory;
SolverFactory<JobShopSchedule> solverFactory =
SolverFactory.createFromXmlResource("solverConfig.xml");
Solver<JobShopSchedule> solver = solverFactory.buildSolver();
JobShopSchedule solution = solver.solve(problem);
4) Solver-Konfiguration / Moves (CH + Local Search + problemnahe Moves):
<solver ...>
<environmentMode>REPRODUCIBLE</environmentMode>
<randomSeed>37</randomSeed>
<constructionHeuristic/>
<localSearch>
<unionMoveSelector>
<changeMoveSelector/>
<moveListFactory>
<moveListFactoryClass>
de.liebau.ablaufplanung.solver.OperationOrderRescheduleMoveListFactory
</moveListFactoryClass>
</moveListFactory>
</unionMoveSelector>
</localSearch>
</solver>
Die gezeigte XML ist die solverConfig.xml, also die Konfiguration für den Solverlauf in Timefold/OptaPlanner. Dort werden u. a. Laufmodus und Seed, die Phasen (Construction Heuristic, Local Search) sowie die Move-Definitionen (changeMoveSelector und die eigene MoveListFactory) festgelegt. Domänenmodell (Planning Entity/Variable) und Constraints (ConstraintProvider) liegen dagegen im Java-Code.
Die problemnahen Moves arbeiten analog zu lokalen Strukturverbesserungen beim TSP: Statt nur die Startzeit (startGrain) einer einzelnen Operation zu verändern, wird eine kleine strukturelle Änderung (z. B. Tausch unabhängiger benachbarter Operationen in einer topologischen Reihenfolge) mit einer erneuten seriellen Einplanung kombiniert.
Im PoC wird der Solver zusätzlich per JSON parametrisiert (Szenario, Kapazität, Seed, Zeitlimit) und liefert JSON-Output mit Seed-Qualität und Endergebnis. Dadurch bleibt der Weg von der Startlösung zum Ergebnis gut nachvollziehbar.
Der Solver läuft in diesem Fall weiter, da nur eine Warnung vorliegt. So bleibt die Trennung klar: Drools prüft/klassifiziert Fachregeln, Timefold optimiert die zulässige Planung.
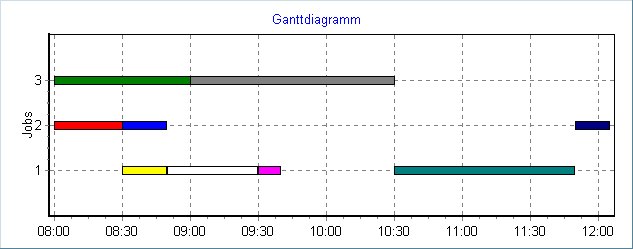
Beispielausgabe (Konsole, 3-MA-Fall):
Seed : deterministic feasible serial seed applied (orders=1, makespan=305 min)
Score : 0hard/-245soft
Makespan : 245 min
Hard checks: precedenceViolationMinutes=0, capacityOverload=0
Operation plan (sorted by start):
O5 (J2) start= 0 end= 30 dur= 30 demand=2
O8 (J3) start= 0 end= 60 dur= 60 demand=1
O1 (J1) start= 30 end= 50 dur= 20 demand=1
...
O7 (J2) start=230 end=245 dur= 15 demand=3
Beispielausgabe (Konsole, 4-MA-Fall):
Seed : deterministic feasible serial seed applied (orders=1, makespan=180 min)
Score : 0hard/-170soft
Makespan : 170 min
Hard checks: precedenceViolationMinutes=0, capacityOverload=0
Operation plan (sorted by start):
O1 (J1) start= 0 end= 20 dur= 20 demand=1
O5 (J2) start= 0 end= 30 dur= 30 demand=2
O8 (J3) start= 0 end= 60 dur= 60 demand=1
...
O4 (J1) start= 85 end=165 dur= 80 demand=3
Optional: regelbasierte Vorvalidierung (Drools)
Vor dem Solve-Schritt kann eine Rule Engine wie Drools die Eingabedaten prüfen und Befunde klassifizieren. So bleiben Fachregeln unabhängig vom Solverkern. Typische Checks sind Rasterverträglichkeit (5-Minuten-Grains), Kapazitätsgrenzen, fehlende Referenzen in Vorrangrelationen oder offensichtliche Modellierungsfehler. Warnungen lassen den Lauf zu, Fehler brechen vor dem Solve-Schritt ab.
Beispiel (Warnung, demand == capacity):
Scenario validation (Drools):
- WARNING [OPERATION_EXCLUSIVE_CAPACITY] operation uses full capacity alone: O4
Seed : deterministic feasible serial seed applied (orders=1, makespan=300 min)
=== Scheduling PoC (Timefold) ===
Score : 0hard/-230soft
Makespan : 230 min
Hard checks: precedenceViolationMinutes=0, capacityOverload=0
...
Der Solver läuft hier weiter. Damit bleibt die Trennung klar: Drools prüft Eingaben, Timefold erzeugt die Planung.
Robuste Pläne statt nur minimalem makespan
In realen Anwendungen sind Dauern, Freigaben und Verfügbarkeiten selten exakt bekannt. Ein Plan mit minimalem makespan ist daher nicht automatisch der betriebspraktisch beste Plan, wenn schon kleine Störungen (Verspätungen, Nacharbeit, Ausfälle) zu starken Kaskadeneffekten führen.
Ein nächster Schritt nach diesem PoC ist daher die Optimierung robuster Pläne. Typische Erweiterungen sind z. B. Pufferzeiten an kritischen Stellen, die Minimierung von Planinstabilität bei Re-Optimierungen (möglichst wenige Änderungen gegenüber dem Vortagesplan) oder die Bewertung eines Plans über mehrere Störungsszenarien statt nur über einen einzigen Idealablauf.
Methodisch bleibt der Ansatz gleich: Hard Constraints sichern die Zulässigkeit, während zusätzliche Soft Constraints Robustheit und Stabilität modellieren. Das hier gezeigte Solver-Modell ist damit ein direkter Ausgangspunkt für produktionsnahe Planung unter Unsicherheit.
Einordnung aus Sicht des Operations Research
Aus Sicht des Operations Research ist das gezeigte Modell ein Scheduling-Problem mit Präzedenzrelationen (DAG) und einer erneuerbaren Kapazitätsressource (gebundene Mitarbeitende pro Zeitscheibe). Das Ziel „makespan minimieren“ entspricht der Minimierung der Endzeit des letzten Vorgangs. In dieser Struktur ist das Problem ein Resource-Constrained Project Scheduling Problem (RCPSP). Es ist verwandt mit bestimmten Job-Shop-Varianten.
Exakte Verfahren wie MILP/ILP oder Constraint Programming können optimale Lösungen mit Nachweis liefern. Bei realistischen Instanzgrößen und Zusatzbedingungen werden sie jedoch schnell rechenintensiv. In der Praxis dominieren daher heuristische und metaheuristische Verfahren. Zunächst wird eine zulässige Startlösung konstruiert, anschließend wird sie über lokale Suche im Lösungsraum verbessert.
Der PoC illustriert dabei ein typisches Vorgehen: klare Trennung von Zulässigkeit (Hard Constraints) und Optimierungskriterien (Soft Constraints), reproduzierbare Läufe über Seeds sowie nachvollziehbare Ausgaben zur Ergebnisbewertung. Die verwendeten Reschedule-Moves sind OR-typisch, weil sie koordinierte Änderungen erzeugen: eine kleine strukturelle Variation (z. B. Tausch unabhängiger Operationen) wird mit einer erneuten seriellen Einplanung kombiniert und erschließt damit Verbesserungen, die mit reinen Einzeländerungen oft schwer erreichbar sind.
Für produktionsnahe Anwendungen wird das Basismodell meist in drei Richtungen ausgebaut:
- Zielsysteme jenseits des makespan, etwa Termintreue, Prioritäten, Überstundenkosten, Rüst- bzw. Wechselkosten oder Fairness.
- Realistischere Ressourcen: Qualifikationen, Schicht- und Pausenregeln, Kalender, Mehrfachressourcen oder Materialfreigaben.
- Stabilität und Robustheit: Puffer an kritischen Stellen, geringe Planänderungen bei Re-Optimierung sowie Bewertung unter Störungsszenarien statt nur im Idealfall.
Damit eignet sich das Modell als Kern einer datengetriebenen Entscheidungsunterstützung: Szenarien lassen sich systematisch vergleichen (Kapazität, neue Aufträge, Ausfälle), und die Optimierung kann schrittweise von „schnell zulässig“ hin zu „robust und betrieblich stabil“ weiterentwickelt werden.
Weiterlesen
- Timefold als Fork von OptaPlanner: timefold.ai: OptaPlanner continues as Timefold.
- OptaPlanner EOL (Red Hat Build): Red Hat: OptaPlanner End of Life Notice.
- Parkplatzzuweisung als Optimierungsproblem: Dynamic parking space allocation at urban scale: Problem formulation and resolution (2021).
- Parkplatzzuweisung mit Fairness-Kriterium: Min-max fair car-parking slot assignment.
- Überblick zu AGAP: A review on airport gate assignment problems: Single versus multi objective approaches (Omega, 2019).
- Praxisbeispiel Gate und Standzuweisung: Copenhagen Airport Gate and Stand Assignment.
- Offene Datenbasis für Gate und Standzuweisung: SFO Gate and Stand Assignment Information.
Quelle des Originaltexts: Web Archive (2005)
AMS Subject Classifications: 90B30, 90B35